In MELLODDY, several of the world’s largest pharmaceutical companies aim to leverage each other’s data by jointly training a multi-task machine learning model for drug discovery without compromising data privacy (or confidentiality). In this blog post, we are going to explain how this data is safeguarded. This article has been originally published on MELLODDY’s website.
Federated Learning
The learning framework utilized in MELLODDY follows the principles of Federated Learning [1], which enables the joint modeling of tasks from multiple companies without explicitly sharing the underlying raw training data. In the context of MELLODDY, these confidential training data are composed of compound structures and bioactivity values which are kept hidden from other participants, and only the local model updates (so-called gradients) are shared with a server where these updates are aggregated (e.g., averaged) and the new model is sent back to the participants. In Federated learning, this model represents all the knowledge about the private training data that is shared among all participants. When training ends, every participant can use this common model for their own purposes. In MELLODDY, this process functions a bit differently (more below).
One of the main design principles of Federated Learning is to prevent the leakage of training data. Indeed, MELLODDY participants never share training data explicitly. Yet, for the training take place, some information flow is needed. The key is to find the right balance between privacy and “information leakage”, where privacy takes the upper hand. In Federated Learning, there are two potential sources of information leakage: the gradients shared during training and the predictions of the commonly trained model used after training [2]. For example, gradients can reveal what chemical structures are present in training samples, while model predictions can be used to distinguish already seen training samples from yet unseen testing samples. An attacker can use them to identify and/or reverse-engineer the data through a membership inference attack [3]. An important distinction here is whether, if the attack is successful, a compound or target can be linked to the group of federated run participants or to a single participant.
Multi-Task Learning
Machine learning models developed within MELLODDY are less susceptible to membership attacks due to multi-task learning. In the context of MELLODDY, multi-task learning means that compound bioactivity is predicted on different proteins and phenotypes, i.e., while the inputs are standardized (i.e., a chemical fingerprint) the outputs (i.e., targets with specific assays) might differ per participant. Hence, in contrast to the classical Federated Learning, where the entire model is shared, within MELLODDY, only the first few layers are shared. This constrained information sharing already mitigates membership inference attacks to some extent, as they use the gradients and the final model. For example, gradients closer to the output layer include more information about the bioactivities of a compound, which are not shared between partners.
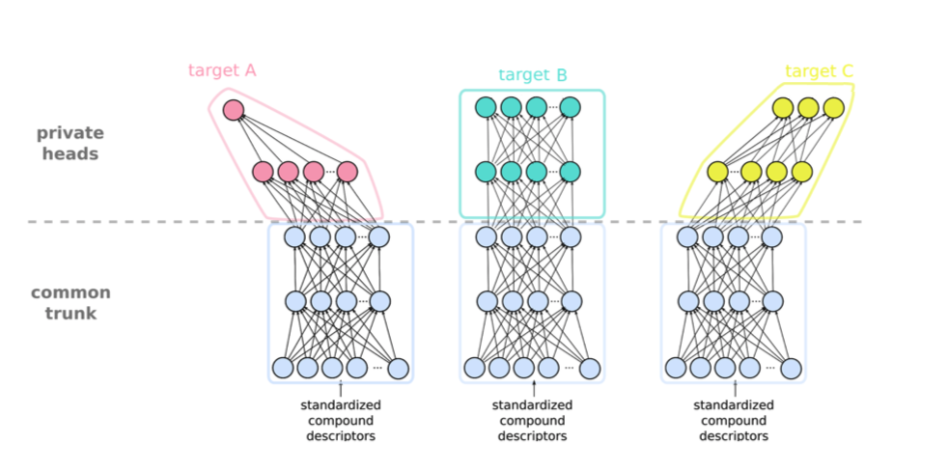
Figure 1: Illustration of Multi-Task Learning: the input and the first layers (so-called trunk) are standardized and common, while the last layers (so-called head) are task-specific and might differ task-wise. The number of layers in this illustration is illustrative.
Secure Aggregation
In addition to the inherent defense provided by multi-task learning, MELLODDY also uses secure aggregation [4] to prevent access to the gradients of an individual partner. This means that a membership attack could only be performed on the aggregated gradients. Therefore, even if the attack is successful, it is difficult for the attacker to attribute the inferred training sample to any partner, which is the main privacy objective in MELLODDY. As such, the participants benefit from a crowd-blended or k-anonymity-like privacy guarantee. Moreover, apart from the individual gradients, even the aggregated model and the gradients are hidden from the central server by using a shared secret known only to the participants.
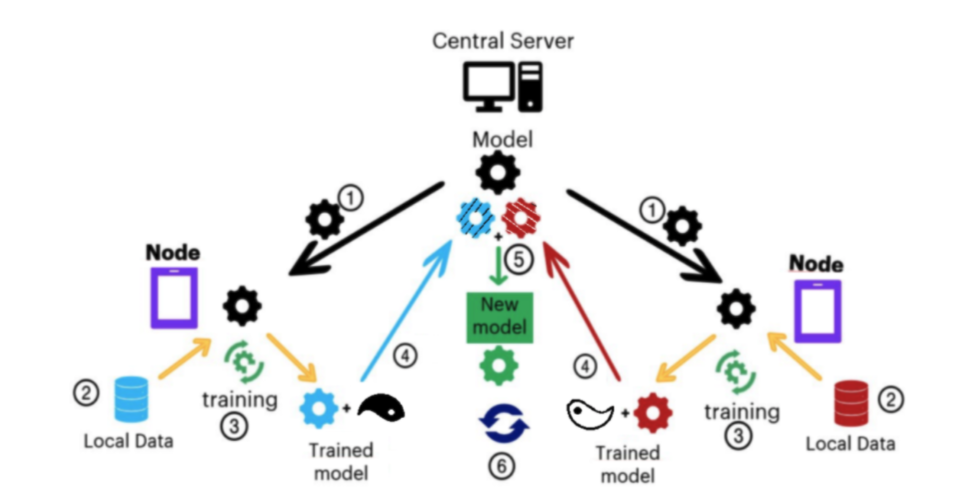
Figure 2: Illustration of Secure Aggregation within Federated Learning: i) the central server broadcasts the model to the participants (step 1), ii) the participants train the model on their local datasets (step 2-3), iii) the participants mask their model updates with pair-wise masks and send them to the central server (step 4), iv) the server aggregates the local models (step 5), and finally v) the whole process repeats (step 6).
Concluding Remarks
MELLODDY has a great potential to accelerate the discovery of new drugs, if pharmaceutical companies are adequately incentivized to cooperate and share their knowledge. Concerns of data privacy and, in general, the lack of trust in the MELLODDY platform would easily deter this cooperation and, therefore, hinder advancements in healthcare.
The privacy team at BME (CrySyS Lab) helps partners build trust in the platform by developing technical solutions that mitigate privacy concerns. Our work is focused on auditing the training algorithms which includes risk analysis. In particular, we develop privacy attacks to measure unintended data leakage (if any) and propose mitigations as well as secure variants of the desired functionalities.
References
[1] – Kairouz, Peter, et al. “Advances and open problems in federated learning.” arXiv preprint arXiv:1912.04977 (2019).
[2] – Rigaki, Maria, and Sebastian Garcia. “A survey of privacy attacks in machine learning.” arXiv preprint arXiv:2007.07646 (2020).
[3] – Hu, Hongsheng, et al. “Membership Inference Attacks on Machine Learning: A Survey.” arXiv preprint arXiv:2103.07853 (2021).
[4] – Bonawitz, Keith, et al. “Practical secure aggregation for privacy-preserving machine learning.” proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security