Ez a blogposzt a második egy három részes sorozatból mely a gépi tanulás adatvédelmi kockázatairól kíván közérthető nyelven egy átfogó képet nyújtani. Az első egy bevezető volt a gépi tanulás világába, ez a létező támadásait öleli át, míg az utolsó rész a lehetséges védekezéseket mutatja majd be.
Gépi Tanulás Összefoglaló
Ahogy azt az előző bejegyzésben mutattuk, a gépi tanulás térhódítása elkerülhetetlen. A tanult modellek évről-évre jobban teljesítenek; egyes területeken már vetekednek az emberi eredményekkel. Ilyen például a bőrrák meghatározása melanóma fotók alapján, ahol egy algoritmus a bőrgyógyászok 87%-ánál jobban diagnosztizált.
A gépi tanuló algoritmusok általában több körösek, míg az adat amin a tanulás alapszik lehet egy helyen vagy elosztva több résztvevő között. Ez utóbbi esetben a résztvevők külön-külön tanítják a modellt, amiket egy biztonságos protokoll összegez. A gépi tanulás minden esetben egy adathalmazon alapszik, ami a tanulás kezdetekor ketté van bontva tanuló illetve tesztelő halmazra. A tanulás a tanuló halmazon történik, míg annak ellenőrzését a tesztelő halmaz segítségével végzik. Egy modell lehet tanulatlan, túl-tanult, illetve a kettő közötti optimális állapotban attól függően, hogy melyik halmazon hogy teljesít: alacsony pontosság mindkét adathalmaz esetén tanulatlan modellre utal míg magas pontosság csak a tanuló halmazon a túl-tanult modellre jellemző.
A tanulási során egy modell a tanuló halmaz tulajdonságait/elemeit memorizálja, így a modell megtanulhat konkrét adatokat/értékeket amik a tanuló halmazban vannak. Amennyiben a tanult modellből szivároghat konkrét adat a tanuló halmazból, az komoly adatvédelmi probléma amennyiben a tanuló adatok között volt bizalmas adat is.
Példa: Arcfelismerés
Manapság egy mobiltelefon a legkisebb részletekig tartalmazza tulajdonosa életét, így nem véletlen, hogy ezen eszközök nagy része le van védve jelszóval. Azonban beütni egy jelszót időigényes folyamat, így nehány éve a mintázat alapú hitelesítés leváltotta a jelszavakat. Ahogy a technika fejlődött, egy még gyorsabb alternatív megoldás jelent meg, mely a másodperc töredéke alatt képes feloldani a telefont. Ez a technológia az arcfelismerés. A felhasznalónak fotót kell készítenie önmagáról különböző szögekből, mely tanuló adatként szolgál egy gépi tanuló algoritmusnak, aminek feladata eldönteni, hogy egy arc a felhasználóé vagy sem (azaz hogy feloldja-e a telefont).
Amerikai kutatók már 2015-ben megmutatták, hogy egy ilyen arcfelismerő modell támadható, mivel visszaállítható az eredeti arc, ahogy azt a következő ábra szemlélteti. A támadás csupán a betanított modellt használja, így a rekonstrukció nem tökéletes, de arra bőven elég hogy a telefon tulajdonosa azonosítható legyen, ami egyértelműen adatvédelmi probléma.

Jelenléti Támadások
A fenti támadás tulajdonképpen a tanuló adathamlaz ‘átlagát’ állapítja meg a tanult modell alapján. Ez célravezető, ugyanis az összes kép a tanuló adathalmazban ugyanazt a személyt ábrazolja. Amennyiben a tanuló adatok jobban különböznek egymástól, az átlagoló támadás nem célravezető. A teljes tanuló adathalmaz visszafejtése a tanult modell alapján nehéz feladat; azonban már az is komoly adatvédelmi kockázatot jelenthet amennyiben lehetséges egy-egy adat jelenlétének a kimutatása abban (Membership Inference).
Példa: Követés
Tegyük fel, hogy egy kutatás Alzheimer-es betegeket követ, hogy előre lehessen jósolni a betegséget (megtanulva, hogy különböző státuszú betegek mennyire térnek el a napi rutinjuktól). Amennyiben kimutatható, hogy valaki napi rutinját használták a modell felépítéséhez, abból rögtön következne, hogy az illető ebben a kórban szenved, ami nyilválvalóan személyes adat.
Angol kutatók 2017-ben épp ezt vizsgálták, és megmutatták, hogy összesített helyadatokból épített modellből meg lehet állapítani, hogy egy adott útvonal benne volt-e a modell tanuló adathalmazában vagy sem.
Példa: Különleges Adatok
Szöveget josoló gépi tanuló algoritmusok szöveges dokumentumokon tanulnak. Ezekben, mint a természetes nyelvben, viszonylag kevés szó fordul elő sűrűn, és nagyon ritka a különleges szavak száma. Példaul telefonszámok, vagy bankszámla illetve kártyaszámok egy szövegben ritkák, ugyanakkor nagyon érzékeny személyes adatnak számítanak. Tehát ha például a Google kereső által használt szöveg kiegészítő algoritmus gmail-es email-eken tanulna, az akaratlanul megjegyezhetne személyes adatokat (amit a lenti ábra is szemléltet).
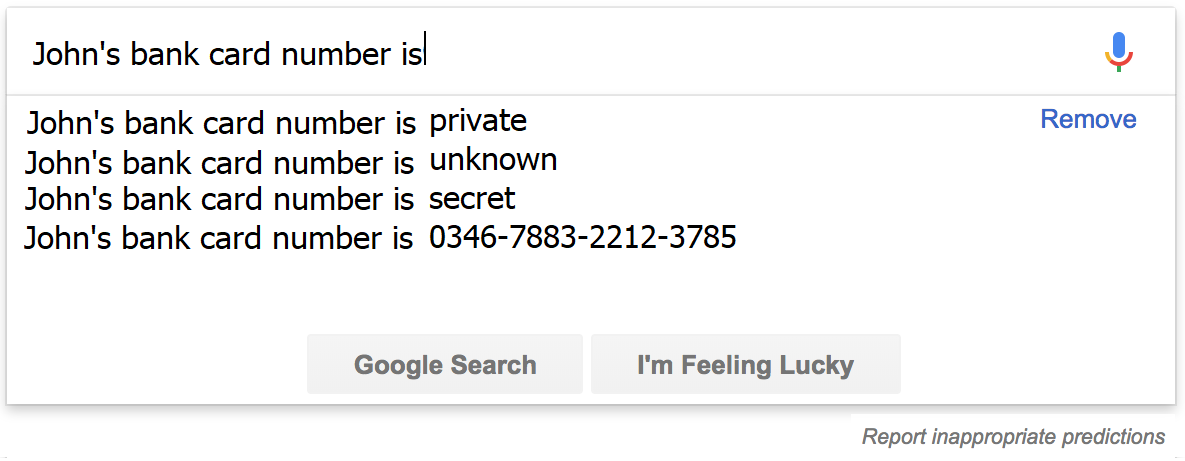
Pontosan ezt mutatták meg kaliforniai kutatók 2018-ban: mesterségesen elrejtettek egy szöveg jósoló modell tanuló hamlazban számsorozatokat, melyek megjosolhatóak voltak a tanult modell alapján.
Tanulásból Eredő Probléma
Amennyiben a modell túl-tanul, a jelenléti támadás várhatóan nem nehéz (ugyanis a modell megjegyez csak a tanuló halmazra jellemző tulajdonságokat). Ugyanakkor amerikai kutatók 2017-ben azt is megmutatták, hogy túl-tanulás egyáltalán nem szükséges a jelenléti támadás sikerességéhez. Egy pennsylvaniai kutatás 2019-ben pedig azt is megmutatta, hogy túl-tanult modell esetén még a legkifinomultabb védekezési technikák (például a differenciális adatvédelem) sem alkalmasak a jelenléti támadás kivédésére.
Megjegyzés: A differenciális adatvédelem (Differential Privacy) garantálja, hogy egy adat jelenléte avagy hiánya nem befolyásolja a modell tanítását jelentős mértékben, amit egy Ɛ paraméter kontrollál. A technikáról bővebben a blog sorozat utolsó részében lesz szó.
Adathalmazból Eredő Probléma
Egy másik fontos tényező a jelenléti támadás hatékonyságában a tanuló adathalmaz asszimetriája: várhatóan könnyebb támadni a kisebb csoportok tagjait, ugyanis a modell az adott csoportról kevesebb adat alapján tanul, így szükségszerűen jobban memorizálja azokat. Erre a problémára világított rá egy georgia-i kutatócsoport többek között azt megmutatva, hogy egy rassz felismerő algoritmus esetén a kisebbségek jelenléti támadása jelentősen sikeresebb mint a fehéreké (mivel belőlük kevesebb van a tanuló halmazban).
Ebből jól látszik, hogy a jelenléti támadás sikerességében jelentős szerepet játszik az adathalmaz nagysága. Ezt be is bizonyította egy szingapúri kutatás felső korlátot adva a jelenléti támadás sikerességére a tanuló halmaz nagysága és a modell bonyolultsága alapján.
Árnyék Modell Támadások
Egy gépi tanuló modell válaszának megbízhatósága eltér olyan adatok esetén amiket még soha nem látott (teszt adat) attól amit már látott (tanuló adat): várhatóan a tanuló adaton a modell magabiztosabb. Ez diákok esetén is így van: amennyiben valamit először látnak, kisebb bizonyosággal állítják, hogy jó-e a válaszuk. A kérdés, hogy ez a kis különbség a modell kimenetében használható-e a tanuló adatok azonosítására.
A választ 2017-ben new york-i kutatók pozitívan megválaszolták árnyék modellek (shadow model) segítségével: a támadó egy árnyék modellt tanít be egy árnyék tanuló illetve egy árnyék tesztelő adathalmaz segítségével, melyek az eredeti modell viselkedését imitálják. Mivel az árnyék modell esetében a támadó tudja, melyik eredmény tartozik árnyék tanuló illetve árnyék tesztelő adatokhoz, a közöttük található apró különbség megtanulásával képes az eredeti modell tanuló adathalmaz elemeinek azonosítására. Ezt a folyamatot a lenti ábra kiválóan szemlélteti.
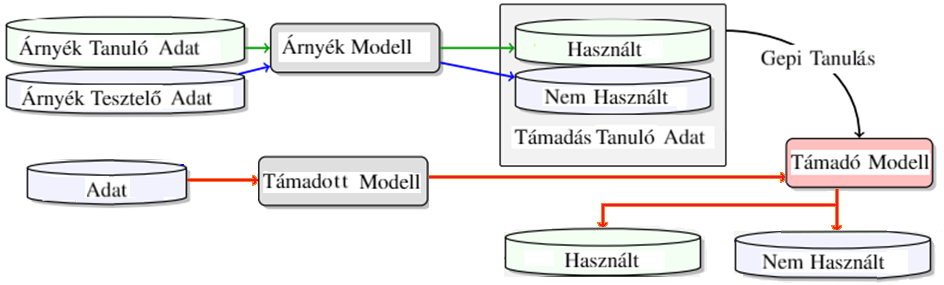
Ha a támadó véletlen találgat, hogy egy adat benne volt-e a tanuló adathalmazban vagy sem, akkor várhatóan az esetek felében lesz igaza. Ennél nyilvánvalóan hatékonyabbnak kell lennie egy jelenléti támadásnak. A fent leírt módon tanított árnyék modellen alapuló támadás hatékonysága például 50-94% (adathamhaztól illetve gépi tanuló algoritmustól függően).
Ez a támadás egy előre betanított modell alapján dönti el, hogy az adott adat része-e a támadott modell tanuló halmazának. Mivel a támadás működik, a helyes döntéshez szükséges információ megtalálható a tanított modellben. Azonban ez az információ csak a tanulási folyamat során kerülhetett oda, így várhatóan maga a tanulási folyamat is tartalmazza azt. Ezt massachusetts-i kutatók meg is mutatták egy hatékony támadást segítségével, mely csupán az utolsó tanulási kör gradiensét (azaz a modell változását) illetve a hozzá tartozó értékelését (azaz a modell javulását) használta.
Visszaállítási Támadások
A jelenléti támadást már 2018-ban továbbgondolták: egy adott adat helyett adatrészhalmazok jelenlétét vizsgálták amerikai kutatók a tanuló halmazban, és képesen voltak magas valószínűséggel meghatározni azokat. Innen már csak egy lépés a teljes tanuló halmaz visszaállítása.
Példa
Tegyül fel, hogy egy hipotetikus támadás eldöntötte egy adathalmazról (hívjuk X-nek), hogy az benne volt a tanuló halmazban. Ekkor hozzáadunk egy adatot X-hez, és újra futtatjuk a támadást. Amennyiben a támadás szerint az új, nagyobb halmaz nem volt benne a tanuló halmazban, kiszedjük a hozzáadott adatot és egy másik adattal növeljük meg X-et. Amennyiben a támadás szerint a megnövelt halmaz benne volt a tanuló halmazban, akkor X-et tovább növeljük, és újra kezdjük az imént leírt procedúrát. Amennyiben már nem tudjuk növelni X-et, akkor az összes tanuló halmazban található elem benne kell hogy legyen X-ben is, így visszaállítottuk azt.
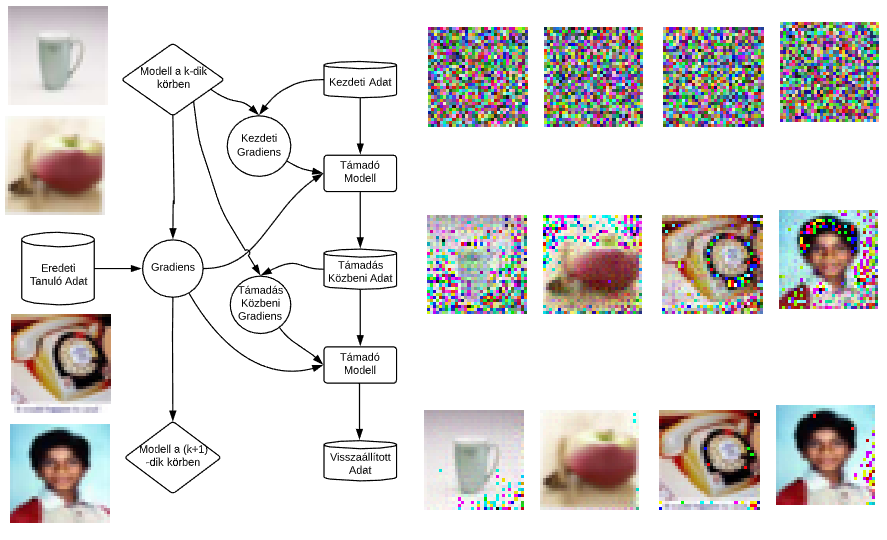
2019-ben massachusetts-i kutatók egy ehhez hasonló támadást mutattak be, mely képes pontosan visszaállítani a tanuló halmazt csupán nehány tanulási kör adatai alapján. A támadás egy adott körben megnézi a támadott modell gradiense (változása) illetve egy véletlen tanuló halmazhoz tartozó gradiens közötti különbséget, és a véletlen tanuló halmazt úgy változtatja, hogy az a különbség csökkenjen. Más szóval míg a támadott gépi tanuló algoritmus a tanuló halmaz alapján optimalizálja a modellt körönként, a támadó gépi tanuló algoritmus egy ilyen körben a ‘tanuló halmazt’ optimalizálja a modell gradiensei alapján. Ezt a folyamatot szemlélteti a lenti ábra is a támadás hatékonyságával.
Tulajdonsági Támadások
A jelenléti támadás egy konkrét, a visszaállítási támadás az összes tanuló halmazbeli elem(ek)et célozta. A harmadik támadási kategória eltér ezektől: a tulajdonsági támadás nem konkrét adatokat céloz, hanem hogy milyen más, a modell funkciója szempontjából nem feltétlenül fontos tulajdonságokat tanult meg a modell a tanuló halmazról. Például hogy mit lehet megtudni a tanuló halmazáról egy nemek felismerésére alkalmas gépi tanulással tanított modellnek. Lehet-e tudni, hogy a tanuló halmazban vannak-e kisebbségek (pl afro-amerikaiak, ázsiaiak) avagy hordanak-e szemüveget. Ez utóbbit néhány kutató megmutatta hogy lehetséges a gradiensek használatával.
Amennyiben közös tanulásról beszélünk, a tanuló adatok osztálya szintén fontos és személyes tulajdonság. Például egy rassz felismerő algoritmus esetén kinek a tanuló halmaza tartalmaz afro-amerikai vagy ázsiai arcokat, vagy egy számfelismerő algoritmus esetén kihez tartozó adathalmazban van 3-as, avagy 5-ös. Ez utóbbra egy illinois-i kutatócsoport mutatott sikeres támadást: egy résztvevő a közös tanulás során képes megállapítani, hogy egy adott körben körübelül hány résztvevőnek volt az adott osztályból adata.
Megjegyzés: A bemutatott támadások nagy része nem kimondottam olyan esetekben voltak demonstrálva, melyek tényleges adatvédelmi kockázatot jelentenek. Ugyanakkor az a tény, hogy ezek a támadások sikeresek az egyszerüsített esetekben arra figyelmeztet, hogy kiemelt figyelmet kell szánni a gépi tanulás érzékeny adatokon való használatánál. Mi a CrySyS laborban aktívan foglalkozunk ilyen támadások elemzésével illetve kivédésével, melyről a következő részen lesz szó.