Ez a blogposzt az első egy három részes sorozatból mely a gépi tanulás adatvédelmi kockázatairól kíván közérthető nyelven egy átfogó képet nyújtani. Ez az első egy bevezető a gépi tanulás világába. A következő a létező támadásokat fogja átölelni, míg az utolsó záró rész a lehetséges védekezéseket mutatja majd be.
A gépi tanulás (Machine Learning) jelentős szerepet kapott az elmúlt években, többek között a széles felhasználási területének illetve az ott elért sikereinek köszönhetően. Több területen is az emberi teljesítmény kihívója lett a szoftver, mely általában a gépi tanulás fejlődésének az eredménye. Ezt mi sem szemlélteti jobban, mint amit a stratégiai játékokkal kapcsolatban láttunk: már 1996-ban az IBM DeepBlue-ja megverte az aktuális világbajnok Garry Kasparov sakk nagymestert, míg 2016-ban a Google AlphaGo-ja tudott felülkerekedni I Szedol 9 danos profi Go játékoson. S ezek a sikerek nem korlátozódnak több ezer éves játékokra: 2019-ben a DeepMind AlphaStar-ja elérte a nagymester címet (99.8% győzelmi arány) a StarCraft II játékban.
Emberi tanulás esetében a megszerzett tudást dolgozatokkal ellenőrzik. Vegyük például a matematikát: a diákok az órán elsajátítanak egy módszert, például a másodfokú egyenlet megoldoképletét. A tanár bemutatja a módszer használatát két egyenleten, majd a következő órán dolgozat formájában számon kéri azt. Amennyiben a dolgozatban a két bemutatott egyenlet valamelyikét kell kiszámolniuk a diákoknak, a tanár nem lehet biztos abban, hogy egy helyes eredményt produkáló diák ténylegesen megtanulta a képletet, vagy csak bemagolta az adott egyenlet megoldását. Következésképpen a tanár egy harmadik, a diákok számára ismeretlen egyenlet megoldását kéri számon: a diákok tudását egy a tanulási folyamatban részt nem vett példán ellenőrzi. Mivel a gépi tanulás az emberit hivatott szimulálni, nem meglepő, hogy ugyanezt az elvet követi az is.
Egykörös Tanulás
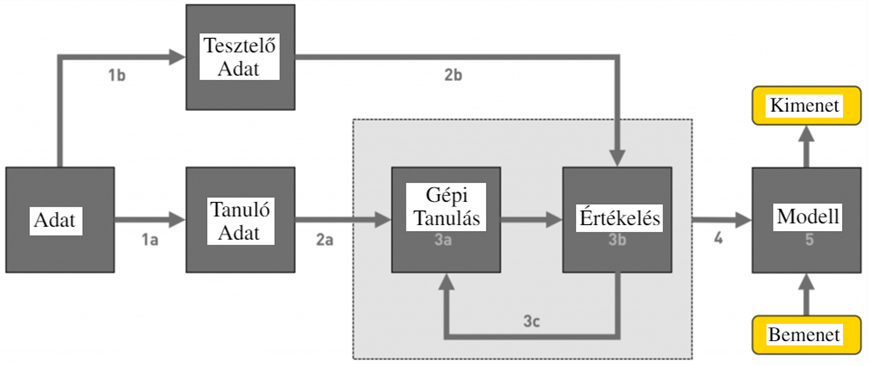
Egy átlagos gépi tanuló algoritmus működését szemlélteti a lenti ábra. A kezdeti adathalmaz két részre lett bontva, a tanuló, illetve a tesztelő adathalmazra. A tanuló adatokon tanul az algoritmus, mely a tesztelő adathalmaz alapján van kiértékelve (azaz mennyire jó a tanult adatokon alapuló algoritmus a teszt adatokon használva). Ezt követően egy végső modell publikálható, mely tetszőleges bemeneteken használva generál kimeneteket.
Példa
Egy évben van 30 nap szabadságom, és érdekelne, hogy ennyi idő alatt meg tudok-e mászni egy 8000 méter feletti csúcsot. A 14 ilyen csúcs közül az Annapurna a legkisebb a maga 8091 méterével. 5 kontinens legnagyobb csúcsához való eljutás idő alapján (lásd táblázat) építek egy modellt, ami meg tudja jósolni egy csúcs magassága alapján az annak megmászására szükséges időt. Amint a lenti ábra mutatja, ehhez 45 napra lenne szükségem, így inkább otthon maradok (ami igen okos döntés, mivel az Annapurna halálozási rátája 33%).
| Név | Csomolungma | Mont Blanc | Kilimanjaro | Denali | Aconcagua |
|---|---|---|---|---|---|
| Magasság | 8 848 m | 4 809 m | 5 895 m | 6 190 m | 6 961 m |
| Idő | 62 nap | 2 nap | 8 nap | 21 nap | 20 nap |
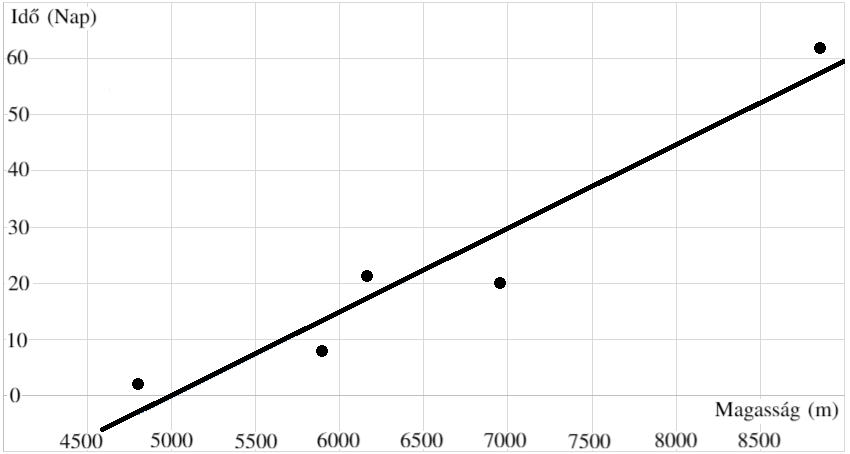
Az ilyen jellegű modellek (amit lineáris regressziónak nevezünk) nagyon elterjedtek a gépi tanulásban: tulajdonképpen a modell lineáris kapcsolatot keres a változók között a meglévő adatok alapján. Ez azt jelenti, hogy a tanuló adatokra próbálunk egy egyenest illeszteni, mely felfed egy trendet a további adatpontok jóslására.
Többkörös Tanulás
Komplexebb modellek esetén a tanulási folyamat (beszürkített zóna az 1. Ábrán) többkörös: a tanulás addig ismétlődik amíg az algoritmus megtanult mindent a tanuló adathalmazról ami igaz a teszt adathalmazra is.
Példa
Egy példa az többkörös tanulásra a filmjavaslatok készítése korábbi film értékelések alapján: tegyük fel, hogy egy gépi tanuló algoritmus minden körben más adat alapján módosítja az ajánlott filmeket. A tanulás előtti modell minden filmet egyforma valószínűséggel ajánl. Ez a hipotetikus gépi tanuló algoritmus az első tanulási körben a filmek műfaját vizsgálja: egy drámát nagyobb valószínűséggel ajánl annak a felhasználónak, akik magas értékelést adott más drámákra. Második körben a szereplőket vizsgálja: ezután a modell magasabb valószínűséggel ajánl olyan filmeket annak a felhasználónak, amiben azok a színészek szerepeltek, akik játszottak a felhasználó által magasan értékelt filmekben is. A harmadik körben a korszakot vizsgálja, ahol a film játszódik, a negyedikben az országot, és így tovább.
Pontosan egy ehhez hasonló feladata volt a 2009-es Netflix álltal kiírt ajánlási verseny résztvevőinek: a Netflix közel 480 ezer felhasználójának 17 ezer filmre adott értékelését tette közzé, amit a versenyben résztvevők felbontottak tanuló (1a) illetve tesztelő (1b) adathalmazokra. Ezután a resztvevők különböző algoritmusokat tanítottak a tanuló adathalmazon (2a), melynek az eredményét a teszt adathalmazon ellenőrizték (2b). Általában a tanulás ismétlődő folyamat, azaz amennyiben az algoritmus (3a) jobban teljesít, mint az előző körben (3b), a tanulás tovább folytatódik (3c). Amennyiben további tanulás kör nem növeli a modell pontosságát (4), a modell betanítottnak számít (5), s más felhasználóknak javasol filmeket az eddigi film értékeléseik alapján.
Egy másik példa a többkörös gépi tanulásra az objektum felismerés: az algoritmus meghatározza a bemenetről, hogy mi az. Ide tartoznak a szöveg felismerő algoritmusok, például egy spam szűrő, illetve a kép felismerő algoritmusok is, melyek például képesek eldönteni az adott CT vagy MRI képről, hogy van-e rajta tumor, vagy hogy a következő közlekedési tábla egy STOP vagy Előzni Tilos.
Többkörös Gépi Tanulás Fajtái
Több különböző gépi tanulási algoritmust lehet használni egy adott probléma megoldására. Néhány ezek közül a teljesség igénye nélkül a döntési fa (Decision Tree), a véletlen erdő (Random Forrest), és a neurális háló (Neural Network). Ezek bonyolultsága a felsorolás sorrendjében nő: van olyan feladat, amit csak a neurális hálók oldanak meg megfelelő pontosággal, ugyanakkor számos feladathoz ágyúval való galambvadászatnak számít a használatuk. Ezt szemlélteti a lenti ábra is.
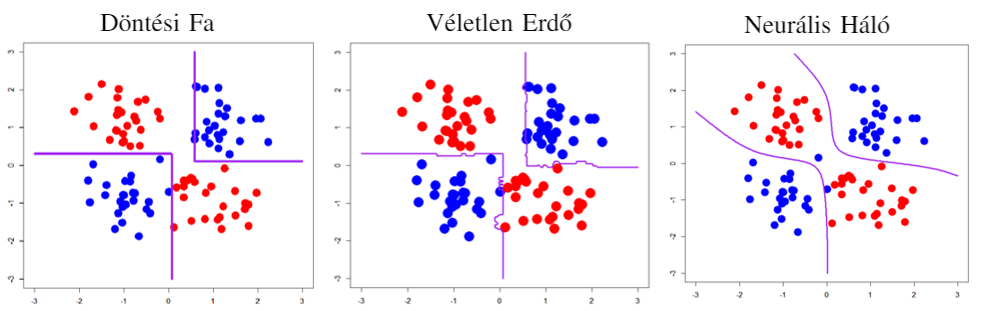
A Körök Közötti Különbség
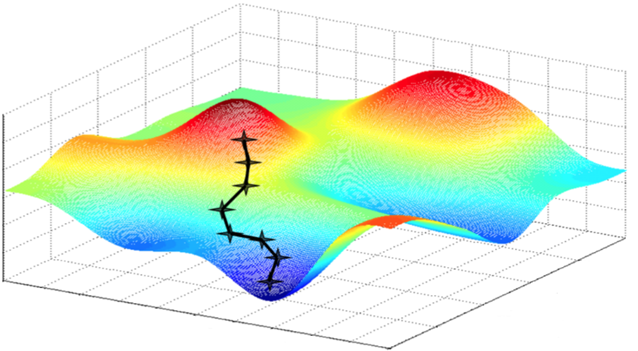
Egy aktuális tanulási kör előtti illetve utáni modell különbségét gradiensnek nevezzük; matematikailag ez a vektor határozza meg az irányt mely legnagyobb javulást okozza az előző modellhez képest. Ezt talán a legjobban úgy lehet leírni, mintha a modell egy túrázó lenne, aki nagy ködben fel szeretne jutni a környék legmagasabb csúcsára. A látási viszonyok miatt a túrázó nem látja, merre is van a hegy csúcsa, csak a közvetlen környezetét látja. Így megnézi, melyik irány emelkedik a legjobban és arra indul el, mondjuk 100 métert. Ezután újra körbenéz, és amennyiben szükséges, változtat a haladási irányán a következő 100 méterre. Ez a folyamat igazából közelebb áll a valósághoz, mint elsőre hangzik: a 100 méter a tanulási ráta (learning rate), és az egész folyamat az úgynevezett Gradient Descent, melyet jól szemléltet a lenti ábra.
Közös Tanulás
Az egyik legfontosabb karakterisztikája a gépi tanulásnak a tanulóhalmaz nagysága illetve a modell pontossága közötti kapcsolat: minél több az adat, annál jobb a pontosság. Azonban az adatgyűjtés adatvédelmi kockázatot jelent: cégek csak úgy, mint egyének nem szívesen osztják meg az adataikat másokkal. Ezt a problémát hivatott megoldani a közös tanulás: több adathalmaz külön-külön használható tanuló adatként egyéni tanulásra, ugyanakkor pontosabb modell érhető el azok összesítésével. Az ilyen tanulást közös tanulásnak nevezzük, ahol a résztvevők a privát adataik alapján ugyanazt a modellt tanítják külön, és minden egyes tanulási kör végén azt valamilyen biztonságos protokoll segítségével összegezik, és megosztják egymás között. Másszóval a közös tanulás során csak a tanított modellek vanak megosztva, a résztvevők adataik nem.
Példa
Így működik például a szókiegészítő (auto-complete) a mobil eszközökön: az eszköz egy lokális modellt tanít a felhasználó gépelése alapján, mely nem képes kiegészíteni eddig nem használt szavakat. Ugyanakkor az összegzett modell képes rá, amennyiben más felhasználók már használták azokat a szavakat.
Tanulatlan & Túl-tanult Modellek
Az adathalmaz kettéválasztása kulcsfontosságú (1a illetve 1b az 1. Ábrán): amennyiben az algoritmus ugyanazon az adathalmazon lenne tanítva és tesztelve, a modell pontossága minden egyes körrel nőne, mivel a modell egyre több és több részletbemenő dolgot tanulna meg az adott adathalmazról. Azonban ha külön adaton teszteljük a modell pontosságát, ott ugyan egy darabig javulást tapasztalhatunk, de elérjük azt a pontot ahol a modell a tanító halmazra specifikusan jellemző tulajdonságokat kezdi el megtanulni. Ezt remekül szemlélteti a 5. Ábra.
Visszatérve a Netflix példához, amennyiben csak magyar felhasználók vannak a tanuló adathalmazban, a modell megtanulja hamar, hogy a felhasználók szeretik a vígjátékokat. Ez nagy valószínűséggel a nem magyar felhasználókra is igaz. Azonban amennyiben a tanulás folytatódik, az algoritmus további részleteket tanul meg, például, hogy a magyarok szeretik a Bud Spencer & Terence Hill filmeket. Azonban ez az információ már nem feltétlenül igaz más nemzetekre. Ezt szemlélteti a lenti ábra, ahol a modell a legpontosabb a szürke vonalak között, mivel a modell minden általános információt megtanult a tanuló adathalmazról a tanulás elején, ami igaz a teszt adathalmazra is, ugyanakkor minden később tanult információ már csak a tanuló adathalmazra igaz, a teszt adathalmazra nem (mivel a tanuló halmazon a pontosságát növeli, míg a teszt halmazon azt csökkenti).
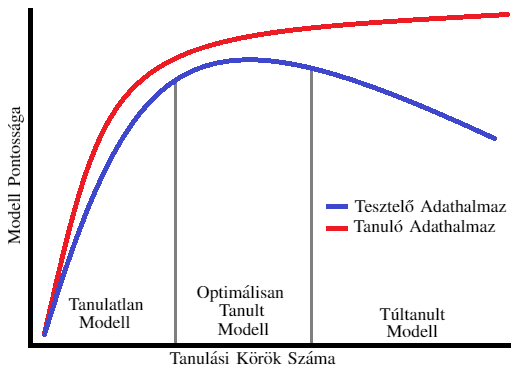
Ezért is különösen fontos, hogy a tanulás az optimális időben befejeződjön. Következésképpen, a gépeket nem szabad hagyni túl sokáig tanulni (overfit). Másfelől viszont korán sem érdemes abbahagyni a tanulást, különben a modell nem tanulja meg azokat az információkat, melyek a helyes működéséhez szükségesek (underfit), ahogy ezt a lenti ábra is mutatja.
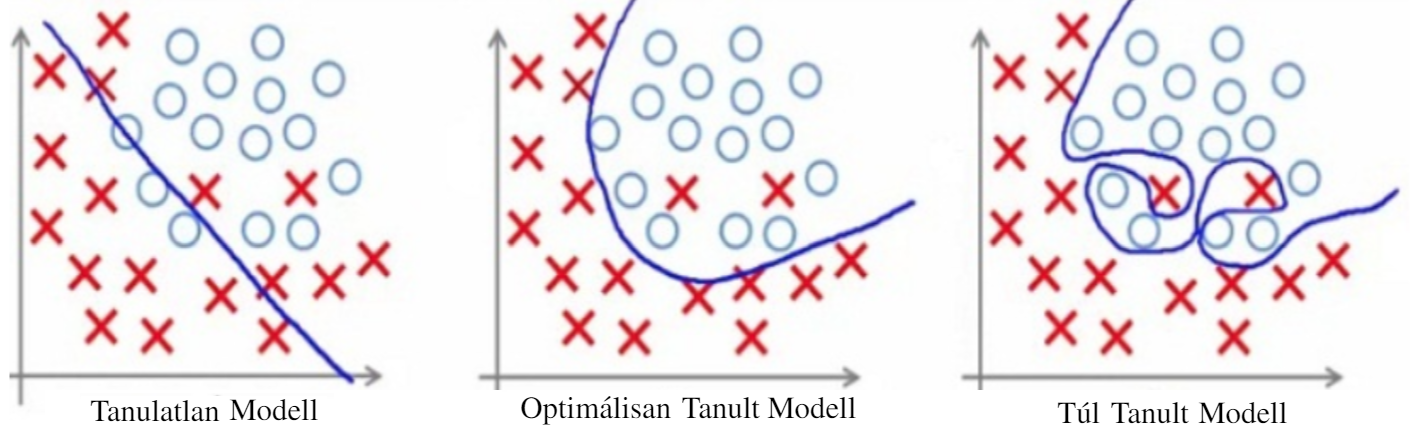
Tehát a tanulási során egy modell a tanuló adathalmaz tulajdonságait/elemeit memorizálja, míg a megszerzett tudás főként a tanulási körök számától függ. Más szóval, a modell megtanulhat konkrét adatokat/értékeket, amik a tanuló adathalmazban vannak. Ebből rögtön következik, hogy a tanult modell potenciálisan szivárogtat adatokat a tanuló adathalmazról, amennyiben azok visszafejthetőek a modellből. A sorozat következő részében pontosan ezzel az adatvédelmi problémával fogunk foglalkozni.