Napjainkban az információs technológiák kiemelkedően fontos szerepet töltenek be mindannyiunk életében. Mind a munkánk, mind a magánéletünk során folyamatos érintkezésben vagyunk digitális szolgáltatásokkal, kezdve a pénzügyeinktől a társkeresésen át a magánbeszélgetéseinkig. Ezek és hasonló szolgáltatások használata során ugyanakkor digitális lábnyomokat hagyunk magunk után, amik komoly adatvédelmi kockázatot is jelenthetnek. A bizalmasan megosztott véleményünk ugyanolyan érzékeny adat, mint a pénzügyi helyzetünk és a szexuális hovatartozásunk, emiatt elengedhetetlen az adataink megfelelő védelme.
Európában a személyes jellegű adatokat törvények védik, amik például azok explicit megosztását is korlátozzák. Ilyen az Általános adatvédelmi rendelet (GDPR), vagy a Digitális szolgáltatások jogszabály (DSA) is. Ennek ellenére rendszeresen történnek adatszivárgások, amiket külső támadók és belső hibák egyaránt okoznak. Látható tehát, hogy pusztán a jogi védelem nem elégséges, és kiegészítő megoldások használata nélkülözhetetlen. Ilyen például a PET (Privacy Enhancing Technologies), ami olyan eljárásokat foglal magában, melyek célja, hogy megvédjék az adatokat a jogosulatlan hozzáféréstől.
Ebben a cikkben a gépi tanulás adatvédelmi kockázataira fókuszálunk, és számos támadás ismertetése mellett bemutatjuk az egyik legelterjedtebb és leghatásosabb védekezési PET mechanizmust, az úgynevezett differenciális adatvédelmet.
Gépi Tanulás
Már-már naponta hallunk híreket, hogy hogyan és mire használják az internet óriások (pl. Google, Microsoft, Apple, Amazon) az általuk begyűjtött potenciálisan érzékeny és személyes adatokat. Ide tartozik a gépi tanulás is, ami a mesterséges intelligencia egyik alterülete. Szemben a klasszikus algoritmusokkal, ahol a döntés a programozó kezében volt, a gépi tanulás során a modell kimenete a tanításához használt adathalmaztól függ. A modell általánosítható mintákat, összefüggéseket keres az adatok között, amik alapján döntést hoz olyan adatokról is, amik nem voltak felhasználva a tanítás során.
A tanítás körönként zajlik, ahol a modell frissítéseket a gradiensek határozzák meg. A gradiens egy olyan apró változás, ami a legnagyobb javulást okozza a modellnek. A többkörös tanítást egy túrázóval lehet a legjobban szemlélteti, aki nagy ködben szeretne lejutni egy hegyről: mivel a völgy nem látható, így elindul abba az irányba, amelyik a legjobban lejt. Egy idő után újra körbe néz, és amennyiben szükséges, változtat a haladási irányán, amig nem érkezik meg a völgybe.
A fenti hasonlatban a túrázó a modell, míg a táj annak a hibája (magas – alacsony). A mozgás pedig a modell paramétereinek a frissítése oly módon, hogy az csökkentse a tanító adatokhoz tartozó hibát. Ebből az is látható, hogy annál pontosabb egy modell, minél több példán lett tanítva. Másfelől, amennyiben túl sokáig fut a tanítás, a modell megjegyezhet konkrét adatpontokat. Ez a jelenség komplex modelleknél is fennáll (túltanulás nélkül), ahol az adatok implicit módon beleszövődhetnek a modell több millió paraméterébe.
Adatvédelmi Támadások
Számos kutatás igazolta, hogy a gépi tanuló modellek megtanulhatnak nem kívánt információkat is. Például konkrét adatpontok memorizálása minden mély neurális háló esetén kimutatható tagsági támadásokkal. Az effajta memorizálás ugyan nem tűnik komoly adatvédelmi kockázatnak, mégis könnyen elképzelhető olyan eset, ahol ez az érzékeny adat szivárgásához vezethet. Ha kiderülne valakiről, hogy használták az adatát egy súlyos betegséget diagnosztizáló modell tanításához, akkor nagy valószínűséggel megtudnánk, hogy az illető abban a betegségben szenved.
A tagsági támadás működési elve könnyen illusztrálható. Képzeljük el, hogy egy kisiskolás most tanulja az összeadást. A tanár példákon keresztül mutatja be a műveletet, pl. 1+1=2, 3+6=9, és 5+5=10. A következő órán a dolgozatban két kérdés szerepel: mennyi 2+3, illetve 5+5. Mivel utóbbi benne volt a diák tanuló halmazában, így azt sokkal határozottabban oldja meg, mint az ismeretlen feladatot. A gépi tanuló modellek is így működnek, azaz magasabb magabiztossággal döntenek a tanító adataikról, és ez ki is mutatható statisztikai tesztekkel.
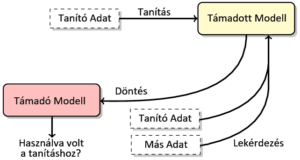
A tagsági támadásnál erősebb adatvédelmi támadások is léteznek, ilyen például a visszaállítási támadás, ami teljes adatpontokat tud rekonstruálni a már tanított modellből. A támadás gyakorlatilag kifordítja a tanulási folyamatot, és nem egy véletlen modellt optimalizál az adott tanuló adatokhoz, hanem egy véletlen adathalmazt optimalizál egy tanult modellhez. Bővebben, az eredeti tanulási folyamat során a modell paraméterei úgy változnak, hogy annak a hibája minimális legyen a tanuló halmazon. Ezzel szemben a támadó egy véletlen adathalmazt módosít úgy, hogy az ahhoz tartozó hiba szintén minimális legyen a támadott modellen. Így a tanítás végére a támadó visszakaphatja az eredeti tanító adatokat.
Adatvédelmi Védekezések
A gépi tanuló modellek adatvédelmi sérülékenységeit többféleképpen lehet csökkenteni. A legkézenfekvőbb megoldás az adathalmaz vagy a modell kimenetének a manipulálása, ugyanis az adatok előfeldolgozásával és a végeredmény utófeldolgozásával a lehetséges adatvédelmi támadások hatékonysága is csökkenthető. Az előbbire példa az érzékeny adatok törlése, és hamis adatok hozzáadása, az utóbbira pedig a kimenetek kerekítése vagy a számosságának a minimalizálása.
A modell megválasztása is fontos, ugyanis különböző modelleknek más és más a sérülékenységi szintjük. Ezeken kívül vannak olyan módszerek is melyek a modell tanítása során alkalmazhatóak, például a modell tanultságának és a paramétereinek a kontrollálása. Ilyen megoldás a tanulás korai megállítása és a paraméterek kerekítése, ritkítása, illetve megnyírása.
Ezek a védekezési módszerek a gyakorlatban ugyan jól működnek, de nagyrészük nem rendelkezik elméleti háttérrel, és csupán informális, empirikusan demonstrált adatvédelmi garanciát nyújtanak. Így hatékonyságukat nem lehet matematikai garanciákkal biztosítani.
Differenciális Adatvédelem
A korábbi megoldásokkal szemben, a differenciális adatvédelem (Differential Privacy) bizonyított és mérhető garanciával jár, melyet kidolgozott matematikai hátterének köszönhet. Lényegében ez a technika garantálja, hogy két modell kimenete hasonló abban az esetben, amikor azok tanuló adathalmazai csupán egy elemben térnek el.
A két modell hasonlóságát egy epszilon paraméter jelzi: minél kisebb ez a szám, annál megkülönbözhetetlenebb azok kimenete egymástól. Ezt a hasonlóságot zaj hozzáadásával szokták elérni. Míg zaj nélkül a modellek kimenetei eltérőek, túl sok zaj hozzáadása után azok statisztikailag azonosak lesznek (mindkettő véletlen). Tehát minél több a felhasznált zaj, annál hasonlóbbak a kimenetek, ezért annál erősebb az adatvédelmi garancia. A zajt több helyen is hozzá lehet adni a tanítási folyamathoz, így a tanuló adatok, a modell kimenete, illetve a gradiensek egyaránt zajosíthatóak.
Az adatvédelmi garancia fókuszát a tanulóhalmazok különbsége határozza meg. Amennyiben csak annyi az eltérés, hogy egy konkrét adatot használnak-e a tanításhoz vagy sem, akkor az adatvédelmi garancia az elemek létezésére van kiélezve. Más szóval, egy ilyen differenciális adatvédelmet használó modell esetén bizonyítható, hogy egy adat jelenléte nem befolyásolja jelentős mértékben a modell tanítását és kimenetét. Következésképpen, a differenciális adatvédelem megfelelő védelmet nyújt a jelenléti támadásokkal szemben is.
Elterjedése
Miközben a differenciális adatvédelem elrejti a modellben az érzékeny, egyedi adatokra jellemző információkat, az hatással van a modell pontosságára is. Ugyanis a hozzáadott zaj elkerülhetetlenül torzítja a megtanulni kívánt (egész adathalmazra jellemző) statisztikai tulajdonságokat is. Másfelől, a zaj mennyiségének a mértéke kontrollálható; ebben a kompromisszumban rejlik a differenciális adatvédelem népszerűségének titka.
Manapság több kutatás foglalkozik ezzel az eljárással. Sőt, közismert cégek, mint például a Google, a Microsoft vagy az Apple, az aktív kutatás mellett számos ismert termékükbe építettek be differenciális adatvédelmi elveket. A kutatások célja a garancia pontosabb becslése, a garancia hatékonyabb elérése, illetve a differenciális adatvédelem adoptálása más releváns gyakorlati problémákra, ahol az eredeti eljárás nem kielégítő.
Következésképpen, a differenciális adatvédelemnek számos változata létezik. Vannak általánosítások szélesebb használhatósági spektrummal, vannak változatok speciális esetekre, illetve vannak erősebb vagy gyengébb garanciát nyújtók is. Ugyan a kifejezés csak 16 éves, a Google Scholar-on mégis több mint 35.000 találat (publikáció) van a “differential privacy” kulcsszóra. Ennyi találat mellett komoly kihívást jelent elkezdeni foglalkozni ezzel a gyorsan fejlődő és igen fontos tudományterülettel. Sőt, adatvédelemi szakértőknek is nehéz eligazodni a differenciális adatvédelem változatai között, ugyanis több olyan módosítás létezik, amelyek ugyan különböző adatvédelmi garanciát nyújtanak, de nevükben mégis azonosak, vagy éppen ellenkezőleg, jelentésük ugyanaz, de a nevük eltérő.
Rendszerezése
A fent említett inkonzisztenciák és egyéb anomáliák potenciálisan gátolják a differenciális adatvédelem szélesebb körű adoptálását, ami egy adatvédelmi szempontból kevésbé biztonságos társadalmat eredményezhet. Ennek megfelelően egy, a területet áttekintő, összefoglaló, és rendszerező dokumentum elengedhetetlen a hatékonyabb navigáció érdekében.
Ezen igényt felmérve és a problémára reagálva írtuk meg társszerzőmmel a Guide to Differential Privacy Modifications című tavaly megjelent könyvet, ahol több mint 250 differenciális adatvédelmi definíciót rendszereztünk intuitív és szemléletes módon hét dimenzióba. A könyv egyúttal a definíciók (korábbról ismert és számos új) kapcsolatát is részletezi, azaz a relatív erejüket és viszonyukat. Így, hogy melyik változat mit implikál, illetve melyik melyik kiterjesztése, az egy helyen és gyorsan megtalálható.
Az egyes dimenziók az eredeti definíció lehetséges változtatásainak különböző módjait reprezentálják. Mivel ezek egymástól páronként függetlenek, így szabadon kombinálhatóak, ergo egy definíció több dimenzióba is tartozhat. Ráadásul ez a rendszerezés egy receptet is ad új definíciók alkotásához, amikre a gyakorlatban is szükség lehet. Így nem csak a meglévő irodalmat rendszerezi, hanem irányt mutat a jövő kutatásai számára is.
Kitekintés
Reakcióként a manapság jellemző invazív adatgyűjtési trendekre, a differenciális adatvédelemi elveket követő vállalatok visszaszerezhetik felhasználóik bizalmát és megnyugtathatják őket az adataik megfelelő védelméről. Ehhez azonban mind a cégeknek, mind a végfelhasználóknak ismerniük kell ezt a PET megoldást. Többek között ezt a célt szolgálja a megújult Privacy Enhanching Technologies angol nyelvű tárgy a Budapesti Műszaki és Gazdaságtudományi Egyetemen (BME), mely bemutatja és népszerűsíti a differenciális adatvédelemet és más PET megoldásokat.
Ezek ismerete elengedhetetlen az Adatvédelmi Tisztviselők (DPO) számára, hogy szervezetük az adatvédelmi szabályokkal összhangban kezelje alkalmazottjaik és ügyfeleik személyes adatait. A BME keretein belül működő CrySyS Adat- és Rendszerbiztonság Laboratórium, rendszeresen kínál releváns és naprakész képzéseket, illetve számos kutatási projektben használ differenciális adatvédelemi elveket, amikben gyakran hallgatók is részt vesznek.