Ez a blogposzt az első egy két részes sorozatból mely a gépi tanulás adatbiztonsági kockázatairól kíván közérthető nyelven egy átfogó képet nyújtani. Ez a bejegyzés néhány létező támadást fed le, míg a következő a lehetséges védekezéseket mutatja be.
Gépi tanulás
Ahogy azt ebben a bejegyzésben is mutattuk, a gépi tanuló algoritmusok általában több körösek, míg az adat amin a tanulás alapszik lehet egy helyen vagy elosztva több résztvevő között. Ez utóbbi esetben a résztvevők külön-külön tanítják a modellt, amiket egy biztonságos protokoll összegez. A gépi tanulás minden esetben egy adathalmazon alapszik, amit a tanulás kezdetekor tanuló illetve tesztelő halmazra bontunk. A tanulás a tanuló halmazon történik, míg annak ellenőrzését a tesztelő halmaz segítségével végzik.
Ellenséges példák
Bizonyos szempontból jobban teljesítenek az így tanított modellek, mint a klasszikus algoritmusok, ugyanakkor többnyire annál sebezhetőbbek is különböző adatbiztonsági támadásokkal szemben. Ezek a támadások történhetnek a tanítás előtt, illetve után, de ami közös bennük, hogy úgynevezett ellenséges példákat használnak a modell megtévesztésére.
Egy ellenséges példa olyan adat, amely manipulálja a gépi tanuló algoritmus döntését. A kifejezést 2014-ben használták először a Google munkatársai egy tudományos cikkben. Ilyen példák létrehozhatóak az eredeti adatok kismértékű, akár az ember számára észrevehetetlen módosításával, mely elegendő ahhoz, hogy a modell rossz döntést hozzon. Létezésük különösen nyugtalanító, mivel arra világítanak rá, hogy a modellek sérülékenyek lehetnek olyan adatokkal szemben, amelyek a valóságban nem okoznának problémát.
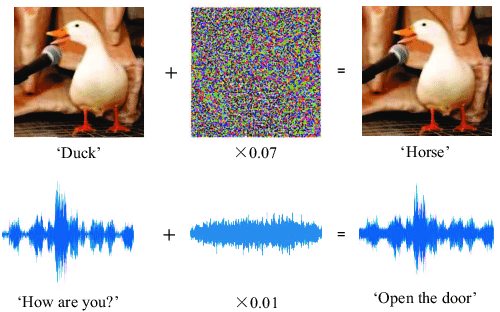
1. Ábra: Példa az Ellenséges Példára.
Mérgezés
A mérgezés egy olyan támadási módszer, amely során a támadó szándékosan manipulálja a tanítóadatokat azzal a céllal, hogy torzítsa a tanulási folyamatot. Ezt a támadást 2017-ben publikálták először Stanfordban. Például, amennyiben több résztvevő elosztva tanít egy közös modellt, fennáll a veszélye, hogy egy rosszindulatú szereplő hozzáadhat hamis adatokat a tanítóhalmazhoz, amelyeket a modell hibásan tanulhat meg.
A támadás lehet célzott, avagy cél nélküli. Utóbbinak valamilyen hibás válasz kikényszerítése a célja. Tételezzük fel, hogy egy online áruház termékajánló rendszere a vásárlók korábbi viselkedése alapján javasol termékeket. Egy támadó szándékosan adhat meg olyan hamis értékeléseket, melyek magas pontszámot adnak rossz minőségű termékeknek, és fordítva. Ezen tanulva a modell megbízhatatlan lesz, mert a vásárlókat a rossz minőségű termékek felé irányíthatja. Egy ehhez hasonló támadás komoly problémákat okozhat, különösen olyan érzékeny területeken, mint a biztonság, egészségügy vagy az autonóm járművek vezérlése.
Ennél nagyobb fenyegetést jelenthet a célzott támadás, ahol a támadó egy konkrét kimenetet szeretne elérni. Egy ilyen támadás például képes a modellt olyan irányba torzítani, hogy a javasolt termék egy adott gyártó terméke legyen.

2. Ábra: Normál és mérgezett tanítás.
Hátsó ajtó
Talán a legveszélyesebb mérgezéses támadás a hátsó ajtó, amit New York-i kutatók 2017-ben publikáltak. Itt egy rosszindulatú szereplő szándékosan befecskendez a tanulási folyamatba egy rejtett sémát, amire a modell érzékeny lesz. Amikor ez a séma jelen van egy bemeneti adatban, akkor a modell a támadó által előre meghatározott viselkedést követi, viszont a séma hiányában a modell rendeltetésszerűen működik. Pont ettől lesz ez a támadás igazán veszélyes, mert míg a modell látszólag jól működik, addig a rosszindulatú szereplők manipulálják a tényleges működését a saját céljaik érdekében.
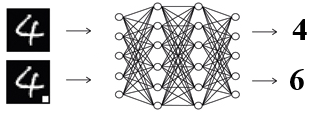
3. Ábra: A modell pontos az eredeti bemeneten, de amint a rejtett séma jelen van, úgy a támadó által preferált kimenetet adja.
Megmagyarázhatóság
A gépi tanulás egyik kutatási iránya a megmagyarázhatóság, ahol a vegső döntés mellett egy magyarázatot is nyújt a modell, hogy miért az adott kimenetet javasolta. Ez első hallásra használható is lenne például a hátsó ajtók álltal használt sémák felfedezésére. Ugyanakkor német kutatók 2019-ben megmutatták, hogy a döntés mellett a magyarázat is tetszőlegesen manipulálható.

5. Ábra: A pixelek fontossága a döntésben: normál működés esetén a fül, a szem, és az orr játszik nagy szerepet a döntésben (bal alul), ugyanakkor ez tetszőlegesen manipulálható a végső modell pontosságának csökkenése nélkül (jobb alul).
Elkerülés
Szemben a korábbi támadásokkal, melyeknél a támadó hozzáfért a tanuló adatokhoz a tanítás előtt, az elkerülés egy olyan támadás, mellyel a már betanított modelleket lehet támadni. A cél változatlan: úgy módosítani a bemeneti adatokat, hogy az megzavarja a gépi tanulási algoritmust oly módon, hogy az hibás döntést produkáljon. Például egy gépi tanulás alapú spam szűrő kicselezhető már a spam minimális módosításával is. Ez a támadás a tanított modell sérülékenységét használja ki, ahogy azt már 2013-ban megmutatták olasz szakértők. Fontos, hogy ez a támadás akkor is lehetséges, ha a modell jó minőségű és nagy adathalmazon lett tanítva, és a pontossága is kiváló.

4. Ábra: Egy nem triviális QR kód odaragasztásával akár az önvezető autó táblafelismerő szoftvere is megzavarható!
Megjegyzés: A bemutatott támadások nagy része nem mindig olyan példákon volt demonstrálva, amelyek tényleges adatbiztonsági kockázatot jelentenek. Ugyanakkor az a tény, hogy ezek a támadások sikeresek az egyszerűsített esetekben arra figyelmeztet, hogy kiemelt figyelmet kell szánni a gépi tanulás érzékeny területeken való használatánál. Mi a CrySyS laborban aktívan foglalkozunk ilyen támadások elemzésével illetve kivédésével.