Ez a blogposzt a második egy két részes sorozatból mely a gépi tanulás adatbiztonsági kockázatairól kíván közérthető nyelven egy átfogó képet nyújtani. Ez a bejegyzés a létező védekezéseket tárgyalja, míg az előző a lehetséges támadásokat mutatta be.
Adatbiztonsági támadások
A különböző adatbiztonsági támadások elleni védekezések elengedhetetlenek a gépi tanulás megbízhatóságát tekintve. Alább néhány ilyen támadást említünk meg, amikről részletesebben az első részben beszéltünk.
- Ellenséges példa: olyan adat, amely manipulálja a gépi tanuló algoritmus úgy, hogy az rossz döntését hozzon ezeken a példákon.
- Mérgezés: olyan támadás, ahol a támadó szándékosan manipulálja a tanítóadatokat, hogy torzítsa a tanulási folyamatot.
- Hátsó ajtó: olyan támadás, ami rejtett sémát fecskendez a tanuló adatokba, aminek jelenléte esetén a modell a támadó álltal preferált döntést hozza.
- Elkerülés: olyan támadás, mely a betanított modelleket támadja úgy, hogy az hibás döntést hozzon a támadó álltal preferált esetben.
Védekezési technikák
Sok ad-hoc illetve bizonyítható metódus létezik, melyek nehezítik a fenti támadások végrehajtását, illetve csökkentik azok hatékonyságát. Ezek, csakúgy mint a támadások, működhetnek a tanítás előtt, közben, illetve után. Lent pár példát mutatunk mindegyik fajtára, majd részletesebben foglalkozunk néhány technikával.
Védekezés tanítás előtt
- Reprezentatív adatok: Sok és jóminőségű tanuló adat használata. Változatos és reprezentatív adatok megnehezítik a támadók számára a modell viselkedésének manipulálását.
-
Adattisztítás: A tanító adatok ellenőrzése. A tanító halmazban való keresése és eltávolítása a rosszindulatú adatpontoknak.
-
Ellenséges tanítás: A tanulóhalmaz kibővítése ellenséges mintákkal. A tanítás ilyen példák haszálatával ellenállóbbá teszi a modellt hasonló támadásokkal szemben.
Védekezés tanítás közben
-
Modell disztilláció: A modell leegyszerűsítése egy kisebb modellre. Egy új, modell tanítása az eredeti (potenciálisan szennyezett) tanulóhalmaz nélkül, amit a nagy (és sérülékenyebb) modell véletlen bemenetein és kimenetein tanul.
-
Aggregált modellek: Több modell használata. A döntés szétosztása több modellre megnehezíti a támadó számára az ellenséges példák generálását, mert azoknak a használt modellek nagy részét egyszerre kell becsapnia.
-
Regularizáció: A modell felesleges paramétereinek a mellőzése. Komlpex modellek képesek több mindent megtanulni, például a rejtett sémákat illetve az ellenséges példákat, így a leegyszerűsítésük kontrollálhatja ezek sikerességét.
-
Ellenséges regularizáció: A támadás nehézségének a maximalizálása. A tanítás során a hiba minimalizálása mellett figyelembe lehet venni és párhuzamosan maximalizálni azt, hogy mennyi adatmódosítással lehet egy hibás döntést kikényszeríteni.
Védekezés tanítás után
-
Anomália detektálás: A modell aktivációinak vizsgálata. Egy támadás a szokásostól eltérő neuronaktivációkkal érheti el a kívánt hibás kimenetet, és ez a szokatlan modell viselkedés felismerhető anomália detekciós eljárásokkal.
-
Magyarázhatóság: A döntés kiegészítése magyarázattal. Egy támadás álltal kikényszerített rossz döntés magyarázata rávilágíthat a modell abnormális viselkedésének az okaira, például a titkos sémára egy hátsó ajtó támadás esetén.
-
Bemenet zajosítás: A bemeneti adatok véletlenszerű átalakítása. Az támadás során használt ellenséges példák illetve a rejtett sémák módosulnak zaj hozzáadásával,ami csökkenti azok hatékonyságát.
Ellenséges tanítás
Zajos tanulóadatok nélkül a modell érzékeny lehet az adatok kismértékű változtatására. Ezt jól szemlélteti az 1. Ábra: a bal oldalon több adatpont esetén kis változtatással kikényszeríthető egy rossz döntés. Ezzel szemben, az ellenséges tanítással tanított modell (jobb oldal) robosztusabb, mivel az adatpontok apró változtatása nem eredményezhet más döntést (mert a modell ilyen adatpontokat is használt a tanítás során).
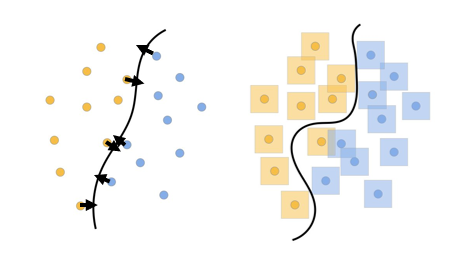
1. Ábra: Illusztráció a robosztus illetve sérülékeny modellre. Bal: döntési határ, mely csak a pontosságra koncentrál. Jobb: robosztus döntési határ, mely kimenete kevésbé érzékeny a bemenet változtatására.
Ellenséges regularizáció
A fenti védekezés a tanítás előtt használható, ugyanakkor hasonló hatás érhető el ellenséges regularizáció esetén is: ahelyett, hogy zajos adatok lennének használva a tanításhoz, a regularizáció maximalizálja a hibás döntéshez szükséges minimális modosítás nagyságát. Ezt lehet többféle képpen is mérni, erre szolgának a normák. Például képek esetén az L1 norma a hibás döntéshez szükséges pixelmodosítások minimális számát maximalizálja, míg az L2 a pixeleken végrehajtott modosítás minimális nagyságát maximalizálja. Ez a minmax methódus a legrosszabb esetre fokuszál, azaz a hibás döntéshez szükséges legkevesebb módosítás méretét maximalizálja.
Bemenet zajosítása
Több adatbiztonságot érintő támadás kivédhető úgy is, hogy zajosított bemeneteken értékeljük ki a modellt. Ezt illusztrálja a 2. Ábra is a mérgezés (bal) illetve elkerülés (jobb) támadás esetén.
Egy egyszerű mérgezés során egy adatpont hamis címkét kap (pl. egy spam levél “nem spam”-ként lenne megjelölve a tanító halmazban). A statisztikai tulajdonságai ennek a mérgezett mintának viszont továbbra is a “spam” osztályra hasonlítanának jobban, amit jól illusztrál a bal felső kép: az adatpont továbbra is inkább a kék “spam” osztályhoz tartozik. Az ilyen kivételeket a modell a tanítás során a döntési határ ráncosításával kezeli, ami szintén megmutatkozik ezen az ábrán. Ugyanakkor a mérgezett adat környezetében a kék “spam” osztály továbbra is dominál, így ha több, véletlen modosítás után ertékelnénk ki a modellt, akkor az többségben “spam” eredményt adna. Ezt a bal középső kép szemlélteti ahol a koncentrikus körök a zaj. Tehát, amennyiben a konkrét minta helyett annak környezetében értékelnénk ki több véletlen mintát, akkor egy robosztusabb döntést kapnánk egy simább döntési határral, amit a bal alsó ábra szemléltet.
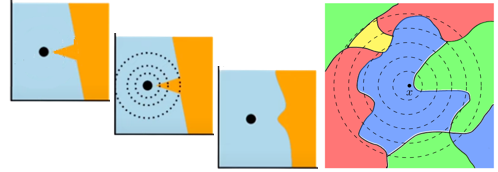
2. Ábra: Illusztráció a bemenet zajisításához. Bal: mérgezés során a döntési határ “ráncos” lesz, míg zajosítás esetén kisimul. Jobb: zajosítás miatt nagyobb módosításra van szükség egy elkerülés támadáshoz.
A bemenet zajosítása az elkerülés támadás ellen is nyújthat védelmet. Itt a támadó egy mintát probál minimálisan módosítani úgy, hogy az egy másik osztályba essen a már tanult modell szerint. A jobboldali ábrán ez jól látható: x-et egy pici jobbratolással át lehet tenni a zöld osztályba. Ugyanakkor, ahogy azt a körök is jelzik, az ellenséges minta környezetében a modell továbbra is az eredeti kék osztályt javasolná többségben.
Komprumisszumok
A modell ellenállóbbá tétele ellenséges példákkal illetve különböző adatbiztonsági támadásokkal szemben több komprumisszummal is jár.
Az egyik ilyen komprumisszum, hogy mekkora pontosságromlást eredményez egy adott védekezés. Ezt jól látható az 1. Ábrán is: a bal oldali modell minden adatpontot jól osztályoz, míg a jobboldali robosztusabb modell esetenként hibás döntést hoz.
Egy másik szintén fontos komprumisszum a robosztusság illetve a számításigény között van. Ugyan ez nincs szemléltetve egyik ábrán sem, de implicit módon ez is megtalálható. Pl. a bemenetek zajosítása (vagy az ellenséges tanítás) esetén minnél több zajosítással van kiértélekekve egy bemenetet (vagy zajosított adattal van tanítva a modell), annál robosztusabb lesz a döntése, ugyanakkor annál több számítási kapacitásra is van szüksége.
Bizonyítható robosztusság
A fent említett konkrét megoldások ugyan empírikusan validálva lettek, de elméleti garanciával nem járnak. Azonban kombinációik kiegészítve más technikákkal nyújthat matematikai garanciát.
Ilyen például a véletlem simítás, amit a Carnegie Mellon egyetem kutatói fejlesztettek ki 2019-ben. Nagyvonalakban a módszerük az ellenséges tanítást illetve a bemenetek zajosítása védekezéseket kombinálja nem-triviális módon.
Bizonyítható robosztusság garantálható más módszerekkel is, mint például a differenciális adtvédelem, melyről itt irtunk korábban. Ezt a technikát elsősorban adatvédelmi támadások kivédésére és adatszivárgás minimalizására használják, ugyanakkor 2019-ben a Columbia egyetem kutatói megmutatták, hogy adatbiztonsági támadások ellen is nyújthat megoldást.
Vízjelezés
Érdekességképpen érdemes megemlíteni a vízjelezést, mint védekezés. Habár ez nem adatbiztonsági támadás ellen nyújt védelmet, de adatbiztonsági támadást vesz alapul a védekezésre. Ahogy azt egy korábbi blogposztban megmutattuk, mind a tanító adatok, mint a modell paraméterei kinyerhetőek a modell kimenetéből. Előbbire védekezéseket itt mutattunk, utóbbi ellen pedig egy hátsó ajtó nyújthat megoldást.
Tételezzük fel, hogy egy cég időt és energiát fektet abba, hogy betanítson egy gépi tanuló modellt. Amennyiben a modellt ellopná egy konkurens, és azt mint sajátja használná, azzal károsulna a meglopott cég, mert az szellemi tulajdonnak számít. Amennyiben a modell tartalmazott egy konkrét hátsó ajtót, annak jelenléte a konkurens cég modelljében eggyértelmű bizonyítékként szolgálna arra, hogy az a modell lopott. Máskülönben nem tartalmazná az eredeti funkcionalitásához nem szükséges speciális hátsó ajtót.
Ugyan a vízjelezés nem előzi meg a modell lopást, de amennyiben az megtörténik, az kimutathatová tenné annak tényét.
Megjegyzés: Fontos említeni, hogy nincs olyan védekezés, ami tökéletes. A védekezés kiválasztása esetenként, fenyegetési modell alapján történik. A fent ismertetett stratégiák kombinációja növelheti a rendszer biztonságát, ugyanakkor fontos a naprakészen tudás is a legújabb kutatásokról, hogy az új támadásokra reagáljunk illetve hogy hatékonyabb védekezéseket alkalmazzunk. Mi a CrySyS laborban aktívan foglalkozunk ilyen támadások elemzésével illetve kivédésével.