Ez a blogposzt az utolsó egy három részes sorozatból mely a gépi tanulás adatvédelmi kockázatairól kíván közérthető nyelven egy átfogó képet nyújtani. Az első egy bevezető volt a gépi tanulás világába, a második a létező támadásokat ölelte át. Ebben a záró részben a lehetséges védekezéseket mutatjuk be.
Az előző részek tartalmából
Az adat alapú gépi tanulás az élet majdnem minden területén jelen van: egyes esetekben már a gépek tanítását is betanított gépek végzik. Ezek a tanuló algoritmusok általában több körösek, míg az adat amiből tanulnak vagy egy helyen van, vagy elosztva több résztvevő között. A gépi tanulás során mindkét esetben ezeket az adatokat kettévágják tanuló illetve tesztelő halmazokra, s logikus módon a tanulás a tanuló halmazon történik. Ez tulajdonképpen azt jelenti, hogy a modell megjegyez az adott adatlamhazra jellemző tulajdonságokat.
Ebből rögtön következik hogy egy tanult modell akár más, a müködéséhez nem szükséges információt is megtanulhat (amit a tulajdonsági támadás próbál kihasználni). Általában az egyes adatok jelenléte is megállapítható a tanuló adathalmazban csupán a tanult modell alapján (melyet az úgynevezett jelenléti támadások céloznak), míg más esetekben annak teljes rekonstrukciója is lehetséges (ami a visszaállítási támadás célja).
Ebben a részben ezek ellen való lehetséges védelmi mehanizmusokat foglalkozunk, a differenciális adatvédelmet beleértve. De mielőtt belevágunk, azt kiemelném, hogy olyan védekezési mechanizmusokat érdemes választani, amik a modell a külvilág felé publikus részeit veszi célba (mivel nem érdemes olyat védeni amihez hozzá se fér a támadó).
Adatok Előfeldolgozása
Ahogy egy emberi sérülést is lehet többféleképpen kezelni (például fájdalomcsillapítás esetén lehet krémet/inekciót lokálisan alkalmazni, kapszulát szájon át, stb), úgy a gépi tanuló modellek adatvédelmi sérülékenységet is lehet többféleképpen és több helyen csökkenteni. A legkézenfekvőbb hely maga az adathalmaz, hisz annak az információ szivárgását kívánjuk mérsékelni.
A gépi tanulás tanításához használt adathalmaz előfeldolgozásával a lehetséges adatvédelmi támadások hatékonysága csökkenthető. Ebből a kategoriából a következő adatvédelmi módszereket emelnénk ki: érzékeny adatok törlése, hamis adatok hozzáadása, zaj hozzáadása a meglévő adatokhoz, illetve dimenziók csökkentése.
Míg az elsőre példa a speciális adatok törlése az adathalmazból, a második célja a jelenléti támadás megbizhatóságának a csökkentése. A hozzáadott véletlen zaj mérete általában a differenciális adatvédelem határozza meg, amivel egy későbbi bekezdésben foglalkozunk részletesebben. Végére hagytuk a dimenziók csökkentést (avagy tömörítést), ami az adatokat formázza át a kevésbé fontos információk eltávolításával.
Végeredmény Utófeldolgozása
A másik kézenfekvő védhető hely a modell végső kimenete, ugyanis a támadások is ezt használják. Osztályozási feladat esetén (például egy kutya/macska képfelismerő modell) a kimenet egy százalék vektor, mely meghatározza, hogy az adott adat hány százalékkal tartozik az egyes osztályokba (például [35.5%, 64.5%]).
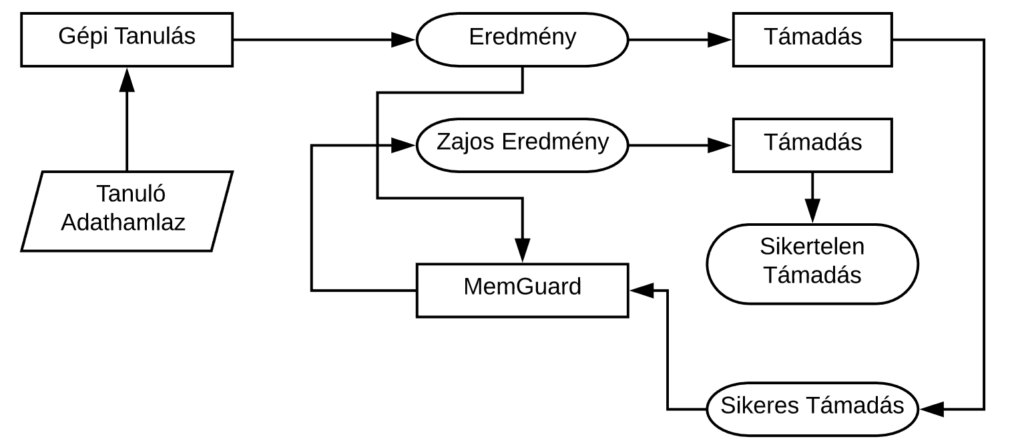
Egy ilyen modellt támadó adatvédelmi támadás hatékonysága könnyedén csökkenthető a végeredmény utófeldolgozásával. Többek között a következő mehanizmusok tartoznak ide: kerekítés (a fenti példa esetén például [40%, 60%]), csak a legvalószínűbb osztály megadása (a fenti példa esetén ‘macska’), illetve zajosítás. Ezutobbit kétféleképpen is hozzá lehet adni: egyik a differenciális adatvédelem, mellyel a blogbejegyzés végén foglalkozunk, másik pedig az ugynevezett MemGuard.
A MemGuard gépi tanuláson alapul, és a ‘legjobb védekezés a támadás’ alapelvet követi, azaz a támadó modellt támadja: tanít egy támadó modellt (például egy jelenléti támadást) a megvédeni kívánt modell eredményeiből, és ahhoz úgy próbál zajt adni, hogy a támadó modellt hatékonyan átverje. Ezt az úgynevezett ellenséges példák (adversarial examples) segítségével tudja megtenni, mely egy olyan támadás gépi tanuló modellek ellen, ami minimális zaj hozzáadásával egy adott elemet hibásan osztályoz (a mi esetünkben a támadó modell hibásan dönt egy adat jelenlétéről a tanuló adathamlazban).
Védekezés Tanulás Előtt
Minden feladat megoldható több fajta modell segítségével. Ezen modellek (például döntési fa, véletlen erdő, neurális háló) más-és-más hatékonysággal oldják meg az adott problémát, ugyanakkor más-és-más az őket támadó algoritmusok hatékonysága is. Így egy adatvédelmi szempontból megfontolt modell választása az adott feladathoz önmagában segít csökkenteni az adatvédelmi támadás sikerességének valószínűségét.
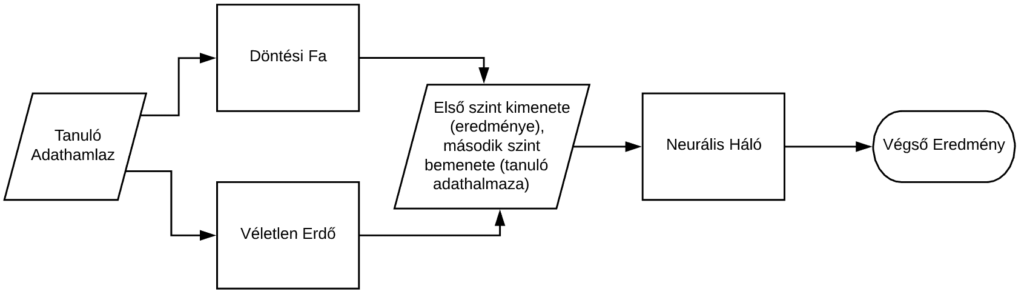
A modell tudatos választásán kívül különböző modellek egymásra pakolása is hatékony megoldás a potenciális támadások kezelésére: például egy feladat megoldható neurális hálóval úgy, hogy annak a tanuló adathalmaza egy döntési fa illetve egy véletlen erdő kimenete. Ezt szemlélteti a lenti ábra is.
Védekezés Tanulás Közben
Eddig csupán olyan védekezési mehanizmusokat elmítettünk, melyek a modellen kívül fejtik ki hatásukat. Ezeken kívül természetesen vannak olyan megoldások is melyek a modell tanulása során alkalmazhatóak. Például a modell tanultságának a kontrollálása (azaz a tanulási folyamat leállítása időben, a túl-tanulási fázis előtt).
További hatékony megoldás az adatvédelmi támadások ellen a modell paramétereinek (súlyainak) illetve a gradienseinek (a modell körönkénti változásának) a kontrollálása. Ide tartozik például a súlyok/gradiensek normalizálása (azaz egység hosszúra konvertálása), ezek kvantálása (avagy kerekítése), illetve a regularizáció (ami ugyan a modell pontosságát hivatott javítani a modell paramétereinek kontrollálásával, de használható az adatvédelmi támadások elleni védekezésre is). Ezutóbbi többféleképpen is megtehető, például kiesésekkel (dropout: a modell paramétereinek véletlenszerű lenullázása) illetve süllyesztéssel (decay: a modell paraméterei nagyságának a megszorítása).
Védekezés Közös Tanulás Esetén
Amennyiben a tanulás közös (az adatok nem egy helyen vannak), úgy a többkörös tanulás esetén az egyénileg tanított modelleket összegezni kell. Az összegzés során információ szívároghat ki, így ezt a folyamatot is érdemes védeni. Ez például megtehető homomorfikus kódolás vagy többrésztvevős biztonságos számítások használatával.
Ezek a kriptográfiai primitívek ugyan nem csökkentik a modell pontosságát, de a használatuk megtöbbszörözi az algoritmusok egyébként is magas számításigényét. Alternatív megoldásként a összegzendő adat mennyiségét lehet limitálni (például a kiszámolt gradiens egy részét összegzik csak), ami ugyan hatással van az összegzett modell pontosságára, de csökkenti a támadások hatékonyságát is. Utolsó megoldásként a zaj hozzáadását említenénk meg, mellyel részletesebben a következőkben lesz szó.
Differenciális Adatvédelem
Az eddig ismertetett védekezési módszerek a gyakorlatban jól működnek, de jóformán semmilyen elméleti háttérrel nem rendelkeznek. Így ezeknek a védekezési technikák hatékonyságára nem tudunk elméleti garancia biztosítani. Ezzel szemben a differenciális adatvédelem (Differential Privacy) bizonyítottan mérhető garanciát nyújt, melyet a kidolgozott matematikai alapjának köszönhet.
Lényegében ez a technika garantálja, hogy két modell kimenete hasonló abban az esetben, amikor azok olyan tanuló adathalmazokon voltak tanítva melyek csupán egy elemben térnek el (például egy elem benne van a tanuló adatlamhazban míg a másik esetben nincs benne). Más szóval minden olyan információt elrejt (mérhető módon) ami egyedi egy tanuló adatra nézve: például az adat jelenléte sem befolyásolja jelentős mértékben a modell tanulását. Következésképpen ez a védekezés a jelenléti támadások ellen hasznos.
A két modell hasonlóságát egy epszilon paraméter jelzi: minél kisebb ez a szám, annál hasonlóbbak a különböző tanuló adathalmazokon alapuló modellek kimenetei. Ezt a hasonlóságot zaj hozzáadásával szokták elérni: zaj nélkül a modellek kimenetei különbözőek, sok zaj hozzáadása után pedig ugyanazok (mindkettő véletlen). Tehát minél több a zaj, annál hasonlóbb a kimenet. Ahogy azt a blogbejegyzés korábbi részeiben említettük, ezt a zajt több helyen is hozzá lehet adni a modellhez: lehet az adathalmazt, a modell tanulási folyamatát, illetve a kimenetet egyaránt zajosítani.
Megjegyzés: A bemutatott védekezések nagy része egy-egy támadás kivédésére (avagy hatékonyságának csökkentésére) fókuszál, így a gyakorlatban ezek kombinálására van szükség. Mi a CrySyS laborban aktívan foglalkozunk adatvédelmi támadások elemzésével illetve kivédésével, különös tekintettel a differenciális adatvédelemre.
FRISSÍTÉS: Általánosítási Hézag
Mi sem szemlélteti e témakör felkapottságát (fontosságát) jobban, mint az, hogy e bejegyzés irása közben egy új tudományos értekezés született a jelenléti támadás sikeressége illetve az általánosítási hézag (a modell pontosságának a különbsége a tanuló illetve a tesztelő adatokon) közötti kapcsolatról: amennyiben a modell x% pontos a tanuló halmazon és y% pontos a teszt halmazon (azaz az általánosítási hézag (x-y)%), akkor bármely jelenléti támadás sikeressége nem lehet több (50+x-y)%-nál (ahol a 50% a véletlen találgatás pontossága). Következésképpen a hézag csökkentése csökkenti a lehetséges támadások sikerességét is.